I'm working on a large blog post investigating the performance characteristics of various PNG decoders across several programming languages. A large part of this work is profiling and benchmarking them.
The first decoder I've been looking at as part of this work is image-rs/png, which is the most downloaded PNG decoder in the rust ecosystem.
To start this kind of work, I like getting some cursory profiles and benchmarks just to see what the libraries are doing. The image I like to start with is this PNG of the periodic table of elements from Wikimedia Commons. This file is in the public domain, so we can do whatever we want with it and it's a pretty good size at ~2.2mb.
{kind=link}
To benchmark image-rs/png, I have to create a binary that uses it, since by itself it's just a library. I've created a simple rust program that looks like this:
fn main() {
const BYTES: &[u8] = include_bytes!("Periodic_table_large.png");
let decoder = png::Decoder::new(BYTES);
let mut reader = decoder.read_info().unwrap();
let bpp = reader.info().bytes_per_pixel();
let width = reader.info().width;
let length = reader.info().raw_row_length();
let mut buffer = vec![0; bpp * width as usize * length as usize];
while let Some(row) = reader.next_row().unwrap() {
buffer.extend_from_slice(row.data());
}
std::hint::black_box(buffer);
}
This isn't perfect, but it works for my purposes right now. A more robust solution would elide the command line altogether and only benchmark the PNG operations themselves, but at the start I just want a rough idea of how the library performs.
I've made a few optimizations to improve the benchmark. Namely, I avoid file IO by using rust's include_bytes! macro, which will load the entire contents of a file into the binary at compile time instead of at runtime, and I pre-allocate the entire output buffer in order to avoid having to resize it during the benchmark.
I'm using std::hint::black_box to make sure the compiler doesn't optimize anything differently just because we aren't actually using the result of the decoding.
To run this benchmark I'm going to use hyperfine, which is a great tool for ad hoc benchmarking of command line utilities.
cargo b --release
hyperfine ./target/release/test-png
gives us
Benchmark 1: ./target/release/test-image-png
Time (mean ± σ): 253.5 ms ± 3.3 ms [User: 211.7 ms, System: 39.9 ms]
Range (min … max): 250.6 ms … 262.4 ms 11 runs
So about 250ms to decode a 2mb image. Is that reasonable? We don't really know -- this is the first decoder we're looking at. Intuitively it feels a bit slow. This is executing on a dedicated Linux server that's not running any other programs.
Out of curiosity, let's profile the binary using perf to see where it's spending its time.
perf record -e cpu-clock ./target/release/test-png
prints
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.047 MB perf.data (1017 samples) ]
and creates a perf.data file. We can read this file using perf report.
perf report
This opens an interactive viewer in our terminal that looks something like this:
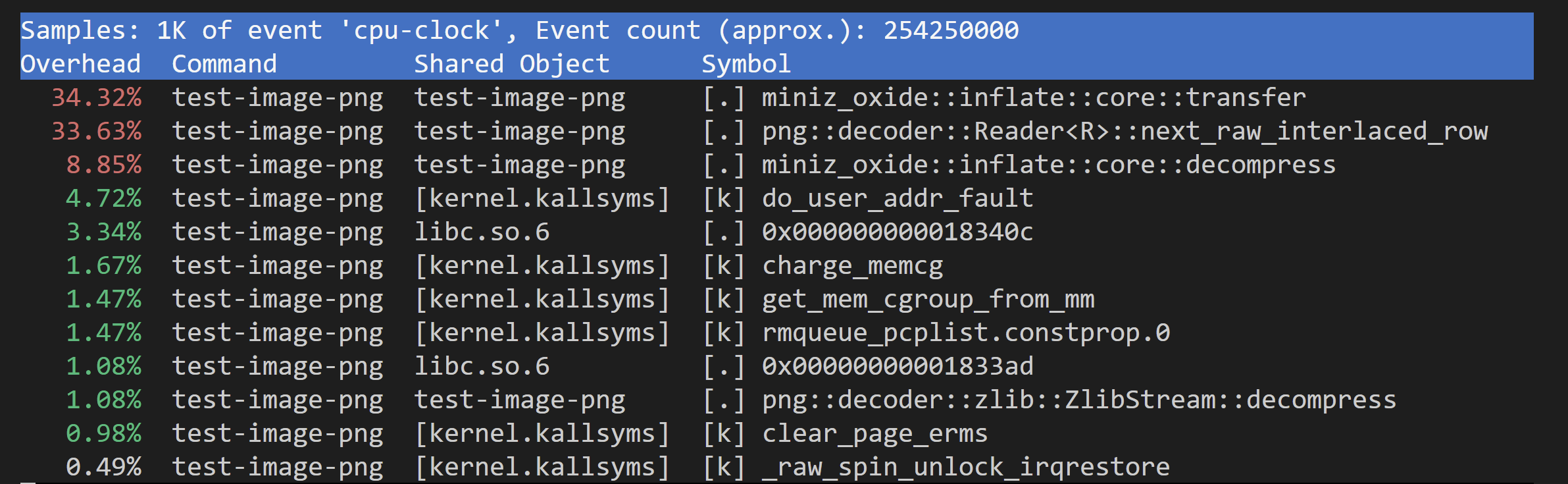
Reading this output isn't too complex. The first column displays a percentage of execution spent in the function. The last column shows the symbol name, which is either the actual name of a function or a memory address.
Does this profile make sense?
The second line looks like it belongs. We'd expect decoding the next interlaced row to be the bulk of the time in a benchmark where we loop over the rows of a PNG file. image-rs/png uses #![forbid(unsafe)], which means that unless they're using an external crate, they likely don't use handwritten SIMD intrinsics to decode PNG filters. LLVM can do ok autovectorizing sometimes, but in general one would expect the equivalent higher level code to not be as fast. It makes sense that this might be a bit slow.
So we expect that most of the time would be spent in png::decoder::Reader<R>::next_raw_interlaced_row, but what about miniz_oxide::inflate::core::transfer?
From the name it's clear that this is coming from the DEFLATE library that image-rs/png relies on. It sounds like all it's doing is transferring data from one buffer to another. If we look at the implementation in miniz_oxide, we can see that's exactly what it's doing:
#[inline]
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
for _ in 0..match_len >> 2 {
out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
out_slice[out_pos + 2] = out_slice[(source_pos + 2) & out_buf_size_mask];
out_slice[out_pos + 3] = out_slice[(source_pos + 3) & out_buf_size_mask];
source_pos += 4;
out_pos += 4;
}
match match_len & 3 {
0 => (),
1 => out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask],
2 => {
out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
}
3 => {
out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
out_slice[out_pos + 2] = out_slice[(source_pos + 2) & out_buf_size_mask];
}
_ => unreachable!(),
}
}
Given a buffer, out_slice, this function will read bytes from within out_slice starting at source_pos and copying them to out_slice starting at out_pos. The specific way it does the copying is a bit more complex, but that's the gist of it.
Our PNG decoder spends 1/3rd of its time copying bytes. That raises a few red flags. Modern memcpy is pretty fast and shouldn't be a bottleneck for our decoder. This function probably isn't being optimized to a straight memcpy, but that's the upper bound we should be targeting, and I think we should be able to get pretty close. Let's look at the disassembly to see what's going wrong. When we look at the disassembly, let's ignore the bottom match statement. That's only executed once per function call and should have a much smaller impact on perf compared to the loop1.
miniz_oxide::core::inflate::transfer:
push rax
cmp r8, 4
jb .LBB0_11
; match_len >> 2
shr r8, 2
.LBB0_2:
; out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
mov rax, rdx
and rax, r9
cmp rax, rsi
jae .LBB0_12
cmp rcx, rsi
jae .LBB0_14
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rdi + rcx], al
; out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
inc rdx
mov rax, rdx
and rax, r9
cmp rax, rsi
jae .LBB0_15
lea r10, [rcx + 1]
cmp r10, rsi
jae .LBB0_16
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rdi + rcx + 1], al
; out_slice[out_pos + 2] = out_slice[(source_pos + 2) & out_buf_size_mask];
inc rdx
mov rax, rdx
and rax, r9
cmp rax, rsi
jae .LBB0_18
lea r10, [rcx + 2]
cmp r10, rsi
jae .LBB0_19
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rdi + rcx + 2], al
; out_slice[out_pos + 3] = out_slice[(source_pos + 3) & out_buf_size_mask];
inc rdx
mov rax, rdx
and rax, r9
cmp rax, rsi
jae .LBB0_20
lea r10, [rcx + 3]
cmp r10, rsi
jae .LBB0_21
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rdi + rcx + 3], al
; source_pos += 4;
add rcx, 4
inc rdx
dec r8
jne .LBB0_2
.LBB0_11:
pop rax
ret
; ... several lines of panic handling code are omitted
Let's break the disassembly down in chunks.
We see a block like this repeated 4 times.
mov rax, rdx
and rax, r9
cmp rax, rsi
jae .LBB0_12
cmp rcx, rsi
jae .LBB0_14
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rdi + rcx], al
Each instance corresponds to the line out_slice[out_pos] = out_slice[(source_pos + X) & out_buf_size_mask]; in the original source. Since we compiled this on Linux, we're using the System V ABI's calling conventions. We pass in out_slice as the first argument. In rust, slices are represented by a pointer and a length. These values get passed to our function in rdi and rsi respectively. The next parameter, in this case source_pos, is passed to the function in rdx. So we move the value of source_pos from the register rdx to the register rax. Then we bitmask it with r9, which contains the value of out_buf_size_mask.
Then we compare that bitmasked value to the length of out_slice stored in the register rsi. The jae instruction, jump if above or equal, does exactly what it sounds like. If rax is greater than or equal to the length, then we jump to .LBB0_12, which sets us up to panic. This is an array bounds check. We have a similar check in the two instructions below, where we check that out_pos is also in the bounds of the slice.
Following that, we move the value at out_slice[source_pos] into the register eax. Then we move the lower 8 bits of that register to out_slice[out_pos].
We repeat this 4 times until we get to the end of the loop.
add rcx, 4
inc rdx
dec r8
jne .LBB0_2
Then we add 4 to out_pos. During iteration we've already been adding to source_pos, so here we just have to increment its value by 1. Then we subtract 1 from our loop counter and jump to the start of the loop if it isn't zero.
You might already be able to see a bit of inefficiency, even if you aren't that familiar with assembly. On every iteration we perform 2 bounds checks per line, for a total of 8 bounds checks per iteration. Bounds checks do add overhead, but much like integer overflow checks, they aren't by themselves that slow. In our case, going out of bounds is exceptional and should never happen during the course of regular execution, which means the branch predictor should do a really good job here.
Typically the problem with integer overflow checks and bounds checks is that they prevent other optimizations, like autovectorization. Perhaps that's what's happening here -- we're doing a lot of bounds checks inside a tight loop and so LLVM can't optimize it that well. Let's see what removing the bounds checks does to the codegen.
Let's start by trying to remove them in safe rust. We can try asserting one large length condition at the start of the function, and hope that LLVM is able to elide the later checks.
The new code looks something like this:
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
assert!(out_slice.len() > (match_len >> 2) * 4 + out_pos - 1);
assert!(out_slice.len() > (match_len >> 2) * 4 + source_pos - 1);
for _ in 0..match_len >> 2 {
out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
out_slice[out_pos + 2] = out_slice[(source_pos + 2) & out_buf_size_mask];
out_slice[out_pos + 3] = out_slice[(source_pos + 3) & out_buf_size_mask];
source_pos += 4;
out_pos += 4;
}
}
Remember we're omitting the final match statement for simplicity. Let's look at the disassembly for the first line in our loop body now.
; out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
mov rax, rdx
and rax, r9
cmp rax, rsi
jae .LBB0_16
cmp rcx, rsi
jae .LBB0_18
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rdi + rcx], al
The bounds checks are still there :/
LLVM wasn't smart enough to elide them based on our assert at the start of the function. Admittedly the check was a bit complex. What if we try asserting at the start of the loop body? That should be a lot simpler for the compiler to reason about.
Our new code looks like this
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
for _ in 0..match_len >> 2 {
assert!(out_slice.len() > out_pos + 3);
assert!(out_slice.len() > source_pos + 3);
out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
out_slice[out_pos + 2] = out_slice[(source_pos + 2) & out_buf_size_mask];
out_slice[out_pos + 3] = out_slice[(source_pos + 3) & out_buf_size_mask];
source_pos += 4;
out_pos += 4;
}
}
Looking at the assembly,
; out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
lea rax, [rdx + rbx]
and rax, r9
cmp rax, rsi
jae .LBB0_12
lea r11, [rcx + rbx]
cmp r11, rsi
jae .LBB0_14
movzx eax, byte ptr [rdi + rax]
mov byte ptr [r14 + rbx - 3], al
The cmp and jae are still there twice for every line in the loop. At this point let's just give up and use unsafe to see if what we're trying to do will actually have a meaningful impact on the codegen. We can use slice::get_unchecked and slice::get_unchecked_mut to elide bounds checks that we know are safe.
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
assert!(out_slice.len() > (match_len >> 2) * 4 + out_pos - 1);
assert!(out_slice.len() > (match_len >> 2) * 4 + source_pos - 1);
for _ in 0..match_len >> 2 {
unsafe {
*out_slice.get_unchecked_mut(out_pos) =
*out_slice.get_unchecked(source_pos & out_buf_size_mask);
*out_slice.get_unchecked_mut(out_pos + 1) =
*out_slice.get_unchecked((source_pos + 1) & out_buf_size_mask);
*out_slice.get_unchecked_mut(out_pos + 2) =
*out_slice.get_unchecked((source_pos + 2) & out_buf_size_mask);
*out_slice.get_unchecked_mut(out_pos + 3) =
*out_slice.get_unchecked((source_pos + 3) & out_buf_size_mask);
}
source_pos += 4;
out_pos += 4;
}
}
We'll add back our original asserts to make sure we don't accidentally do any out-of-bounds reads. What does the codegen for this look like?
example::transfer:
push rax
mov r10, r8
and r10, -4
lea rax, [r10 + rcx]
cmp rax, rsi
jae .LBB0_6
add r10, rdx
cmp r10, rsi
jae .LBB0_7
cmp r8, 4
jb .LBB0_5
shr r8, 2
cmp r8, 2
mov r10d, 1
cmovae r10, r8
add rcx, rdi
add rcx, 3
xor esi, esi
.LBB0_4:
mov rax, rdx
and rax, r9
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rcx + 4*rsi - 3], al
lea rax, [rdx + 1]
and rax, r9
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rcx + 4*rsi - 2], al
lea rax, [rdx + 2]
and rax, r9
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rcx + 4*rsi - 1], al
lea rax, [rdx + 3]
and rax, r9
movzx eax, byte ptr [rdi + rax]
mov byte ptr [rcx + 4*rsi], al
lea rax, [rsi + 1]
add rdx, 4
mov rsi, rax
cmp r10, rax
jne .LBB0_4
.LBB0_5:
pop rax
ret
.LBB0_6:
lea rdi, [rip + .L__unnamed_1]
lea rdx, [rip + .L__unnamed_2]
mov esi, 66
call qword ptr [rip + core::panicking::panic@GOTPCREL]
ud2
.LBB0_7:
lea rdi, [rip + .L__unnamed_3]
lea rdx, [rip + .L__unnamed_4]
mov esi, 69
call qword ptr [rip + core::panicking::panic@GOTPCREL]
ud2
No bounds checks! And a lot fewer instructions than what we started with (55 lines vs 82 originally). So how much faster is the code without bounds checks?
Let's start by cloning the miniz_oxide repo and vendoring our dependencies so we can modify them locally.
If our original Cargo.toml looked like this,
[dependencies]
png = "0.17.7"
we just have to add this section
[patch.crates-io]
miniz_oxide = { path = "../miniz_oxide/miniz_oxide" }
Before we start making changes, lets make a copy of the original binary we used to benchmark so we can use it as a point of comparison for our changes.
cp ./target/release/test-png ./original
Next let's replace the old implementation of transfer with our new one. Then we can build and compare the two implementations.
cargo b --release
hyperfine ./original ./target/release/test-png --warmup 5
which prints
Benchmark 1: ./original
Time (mean ± σ): 255.9 ms ± 4.5 ms [User: 216.9 ms, System: 35.5 ms]
Range (min … max): 251.7 ms … 265.2 ms 11 runs
Benchmark 2: ./target/release/test-image-png
Time (mean ± σ): 254.5 ms ± 5.0 ms [User: 214.7 ms, System: 38.4 ms]
Range (min … max): 250.2 ms … 267.3 ms 11 runs
Summary
'./target/release/test-image-png' ran
1.01 ± 0.03 times faster than './original'
A 1% improvement. These results are barely above random noise, even though we removed bounds checks. We're doing a bit of new work now for the 2 assertions at the start of the function, but that wouldn't be the cause for such a small speed-up. Fundamentally the performance benefits from removing bounds checks aren't helping us here and the optimizer isn't able to do much better even with them gone. If we want to speed up this function, we have to start thinking about the algorithm.
Looking at the assembly, right now our implementation is entirely scalar. We load one array element at a time, mask it, and then copy it to the out position. It should be trivial for the compiler to vectorize this, so what's preventing it?
There's two problems here. First, we mask the array indices with out_buf_size_mask, which means its possible for us to be forced to copy non-consecutive elements from the array. Non-consecutive reads may prevent us from using SIMD here at all.
The other issue is that our data is highly dependent on previous calculations. This is especially apparent when source_pos and out_pos differ by less than 4. We can see this if we think through an example where our array is [1, 2, 3, 4, 5, 6, 7, 8], source_pos is 0, and out_pos is 2. We can pretend we don't do any masking for now. Here's what the code looks like if we substitute concrete values for source_pos and out_pos:
out_slice = [1, 2, 3, 4, 5, 6, 7, 8]
out_slice[2] = out_slice[0]
out_slice[3] = out_slice[1]
# !!!
out_slice[4] = out_slice[2]
out_slice[5] = out_slice[3]
After the first iteration, the array is now [1, 2, 1, 2, 1, 2, 7, 8].
On the third line of our loop, we depend on the results of the first line of our loop. if we tried to load all the values for this iteration at once, we wouldn't get the correct result. We'll have to be really creative if we end up having to work around this dependency in the general case2.
Let's look at the first problem -- masking can cause non-consecutive reads. Is there any way around this? One thing we could look at is the value we're masking by. If it's always the same value, we might be able to make some interesting optimizations. To inspect its value, we can use an ad hoc profiling tool called counts that I really love. To use it, we just need to insert some prints into the code and then pipe the results to counts.
Our new code looks like this:
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
println!("{}", out_buf_size_mask);
for _ in 0..match_len >> 2 {
out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
out_slice[out_pos + 2] = out_slice[(source_pos + 2) & out_buf_size_mask];
out_slice[out_pos + 3] = out_slice[(source_pos + 3) & out_buf_size_mask];
source_pos += 4;
out_pos += 4;
}
}
Pretty simple. Then to use it:
cargo r --release | counts
We run in release mode just because it's prohibitively slow to execute in debug mode. After running this, we get our results:
255047 counts
( 1) 255047 (100.0%,100.0%): 18446744073709551615
Looking at the output, the first number in parentheses is just the line number of the output. The second number is the count for the given value. The last number in the output is the value that we printed.
Based on this, we can see that the mask value is always the same. It looks like some large 64 bit integer. I don't have special 64 bit integers memorized, so lets open up a python repl to see what it looks like in binary.
>>> bin(18446744073709551615)
'0b1111111111111111111111111111111111111111111111111111111111111111'
The number is all ones. Let's check how long it is. The number we're hoping for is 64:
>>> len(_) - 2
64
Ok, so in every case that we call this function for this input, we don't actually do any masking. That's our first problem solved. We can just special case our code when out_buf_size_mask === usize::MAX.
Our next issue is the data dependency when the difference between out_pos and source_pos is small enough that they overlap. Let's see how often this comes up in practice. We can use counts here again to help us:
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
println!("{}", source_pos.abs_diff(out_pos));
// ...
}
cargo r --release | counts
gives us
255047 counts
( 1) 253652 (99.5%, 99.5%): 1
( 2) 516 ( 0.2%, 99.7%): 4
( 3) 150 ( 0.1%, 99.7%): 1200
( 4) 46 ( 0.0%, 99.7%): 24001
( 5) 24 ( 0.0%, 99.7%): 2400
( 6) 16 ( 0.0%, 99.7%): 8
( 7) 12 ( 0.0%, 99.8%): 281
( 8) 12 ( 0.0%, 99.8%): 285
( 9) 11 ( 0.0%, 99.8%): 120
( 10) 10 ( 0.0%, 99.8%): 265
( 11) 10 ( 0.0%, 99.8%): 3600
( 12) 10 ( 0.0%, 99.8%): 4800
( 13) 8 ( 0.0%, 99.8%): 273
( 14) 8 ( 0.0%, 99.8%): 277
( 15) 8 ( 0.0%, 99.8%): 305
... 215 more results omitted
Quite a bit of variance. But if we look at the percentages, 99.5% of cases have a difference of 1. The rest of the cases all have pretty low counts relative to the total. So now we know which case we want to investigate.
Right now we're checking the absolute difference, so we're not actually checking whether out_pos is greater than or less than source_pos. This can affect the changes that we're making, so let's see which one is more common.
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
println!("{:?}", source_pos.cmp(&out_pos));
// ...
}
cargo r --release | counts
255047 counts
( 1) 255047 (100.0%,100.0%): Less
source_pos is always less than out_pos. That means we can just ignore all other cases. That's pretty helpful for our optimization work. Now we can start trying to come up with a fast path:
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
if out_buf_size_mask == usize::MAX && source_pos.abs_diff(out_pos) == 1 {
// our super-fast specialized code goes here
} else {
for _ in 0..match_len >> 2 {
out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
out_slice[out_pos + 2] = out_slice[(source_pos + 2) & out_buf_size_mask];
out_slice[out_pos + 3] = out_slice[(source_pos + 3) & out_buf_size_mask];
source_pos += 4;
out_pos += 4;
}
}
}
Let's revisit our example from before. If we start with an array of [1, 2, 3, 4, 5, 6, 7, 8], let's say source_pos is 0, and out_pos is 1 this time. We don't have to worry about masking because we know the number we're masking by is usize::MAX. Let's think through what the array looks like after 1 iteration.
out_slice = [1, 2, 3, 4, 5, 6, 7, 8]
# [1, 2, 3, 4, 5, 6, 7, 8]
out_slice[1] = out_slice[0]
# [1, 1, 3, 4, 5, 6, 7, 8]
out_slice[2] = out_slice[1]
# [1, 1, 1, 4, 5, 6, 7, 8]
out_slice[2] = out_slice[2]
# [1, 1, 1, 1, 5, 6, 7, 8]
out_slice[4] = out_slice[3]
There's a pretty clear -- and exciting -- pattern here. The range is just converted to be the same value. So if we calculate the end position, we can pretty succinctly do memset(&out_slice[out_pos], out_slice[source_pos], end - out_pos). In rust we can get this codegen pretty easily with out_slice[out_pos..end].fill(out_slice[source_pos]). To calculate the end, we can reuse some of our assertion code from before.
Our new code is
fn transfer(
out_slice: &mut [u8],
mut source_pos: usize,
mut out_pos: usize,
match_len: usize,
out_buf_size_mask: usize,
) {
if out_buf_size_mask == usize::MAX && source_pos.abs_diff(out_pos) == 1 {
let fill_byte = out_slice[source_pos];
let end = (match_len >> 2) * 4 + out_pos;
out_slice[out_pos..end].fill(fill_byte);
source_pos = end - 1;
out_pos = end;
} else {
for _ in 0..match_len >> 2 {
out_slice[out_pos] = out_slice[source_pos & out_buf_size_mask];
out_slice[out_pos + 1] = out_slice[(source_pos + 1) & out_buf_size_mask];
out_slice[out_pos + 2] = out_slice[(source_pos + 2) & out_buf_size_mask];
out_slice[out_pos + 3] = out_slice[(source_pos + 3) & out_buf_size_mask];
source_pos += 4;
out_pos += 4;
}
}
}
We can't compute the fill_byte as an argument to .fill(..) because of rust's borrow checker, so we have to bring out as a separate variable. We have to update the source_pos and out_pos in our fast path because the later match statement depends on their values.
Now let's compile this and compare it to our original binary.
cargo b --release
hyperfine ./original ./target/release/test-png --warmup 5
Benchmark 1: ./original
Time (mean ± σ): 253.1 ms ± 3.1 ms [User: 207.9 ms, System: 43.4 ms]
Range (min … max): 250.5 ms … 260.7 ms 11 runs
Benchmark 2: ./target/release/test-image-png
Time (mean ± σ): 164.8 ms ± 1.3 ms [User: 129.9 ms, System: 34.0 ms]
Range (min … max): 163.7 ms … 168.1 ms 17 runs
Summary
'./target/release/test-image-png' ran
1.54 ± 0.02 times faster than './original'
A 50% improvement. This benchmark is testing how long it takes to decode an entire PNG, so this would be a pretty meaningful optimization. Let's double check this is real and that we didn't break anything by running miniz_oxide's test suite.
cd ../miniz_oxide
cargo t --all
test result: ok. 22 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.01s
# ... full test results omitted
All of the tests pass; this is likely a sound optimization. At this point we should be comfortable making a PR with our changes.
This patch was submitted as #131 to the miniz_oxide repo. It contains a bit more than described here. miniz_oxide has its own benchmark suite, and after looking at it we can make a few small changes to improve performance there as well.
The results of our optimization are pretty striking: for some inputs we see a more than 2x improvement. miniz_oxide is ported from a C library that has roughly the same performance characteristics. What this means is, after our changes, miniz_oxide is now also more than 2x faster than the original C implementation for these inputs.
The relevant benchmarks are:
// before
test oxide::decompress_compressed_lvl_1 ... bench: 89,253 ns/iter (+/- 1,412)
test oxide::decompress_compressed_lvl_6 ... bench: 176,299 ns/iter (+/- 6,266)
test oxide::decompress_compressed_lvl_9 ... bench: 175,840 ns/iter (+/- 3,131)
// after
test oxide::decompress_compressed_lvl_1 ... bench: 83,992 ns/iter (+/- 1,347)
test oxide::decompress_compressed_lvl_6 ... bench: 76,640 ns/iter (+/- 2,288)
test oxide::decompress_compressed_lvl_9 ... bench: 76,791 ns/iter (+/- 1,978)
In practice this was verified by looking at the annotated disassembly in perf report
An implementation of this problem in the general case can be found here, though it ends up not being much faster